
מה הם קבצי Markdown?
קבצי Markdown הם קבצים טקסטואליים פשוטים שעושים שימוש ׳בשפת סימונים׳ (Markup Language) לעיצוב הטקסט (מכאן גם השם). הקבצים האלה נועדו להיות מספיק ברורים וקריאים לאנשים, אבל גם כאלה שמאפשרים המרה לפורמטים מעוצבים כמו HTML.
מה מאפיין קבצי md
- פשטות ו׳קריאות׳ – הקבצים הללו מבוססים על סימונים גרפיים כמו: ׳#׳, או ׳ * ׳ כדי לייצר היררכיה במסמך ולהציג אלמנטים עיצוביים, ככה הקובץ ניתן לקריאה בכל תוכנה.
- חוסר תלות בפלטפורמה – קבצי Markdown ניתנים לעריכה בכל עורך טקסט פשוט כמו Notepad, או תוכנות פיתוח כמו VS Code.
- המרה קלה לפורמטים אחרים – הקבצים האלה מתבססים על סימונים מוסכמים גלובליים ולכן ממש קל להמיר אותם לשפות כמו HTML כדי להציג אותם בדפדפנים בצורה מסודרת ומעוצבת
איך נראה קובץ md?
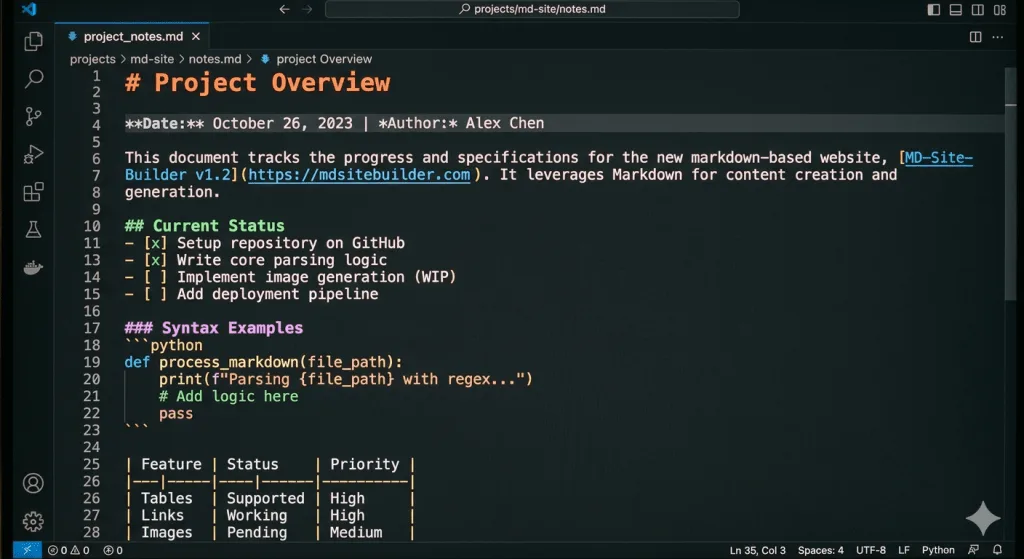
# Personal Blog Project
**created: 14 May 2026**
## The Blog Perpose
The purpose of my blog is to make AI, digital tools, and learning ideas practical, clear, and useful for real people who want to grow, create, and work smarter.
---
## Tasks
- [x] Buy Domain
- [x] Select Hostig Service
- [ ] Write first 5 posts
- [ ] Adding contact infoדוגמאות לסימונים:
- כותרות – מסומנות ב-
#בתחילת שורה, למשל:# כותרת ראשיתאו## כותרת משנית. - הדגשות – מוצגות ע״י כוכביות כפולות לפני ואחרי המילה או המשפט, למשל:
**טקסט מודגש**. - רשימות – מוצגות בסימן
-או*בתחילת השורה. - קישורים – מותגים במבנה של סוגריים מרובעים [אתר] (https://fakeurl.com).
למה זה פורמט כל כך טוב עבור AI?
עבודה עם קבצי md יעילה מאוד בעבודה עם מודלי AI כי זה פורמט ׳יעיל׳ בטוקנים. מודלי שפה לא קוראים מילים, אלא מפרקים אותם לטוקנים (יחידות טקסט קטנות). מסמכים ופורמטים כמו HTML (עם המון תגיות) ׳מבזבזים׳ המון טוקנים. פורמט md הוא פורמט ״רזה״ שעושים שימוש בתווים בודדים (# או *) לעיצוב, זה מאפשר להכניס הרבה יותר מידע בחלון ההקשר (Context Window).
דבר נוסף שמאוד משפיע על היכולת של בינה מלאכותית להבין מידע הוא היררכיה. קבצי md מספקים ל-AI מבנה ברור והיררכי. כותרות עוזרות להבין מה נושא מרכזי ומה משני, רשימות וטבלאות מאפשרות למודלים לסרוק נתונים ולהבין את הקשר ביניהם, ובלוקים של קוד מאפשרים ל״הזריק״ למודלים הנחיות.
והדבר האחרון הוא שרוב המודלים האלה אומנו על מידע מהאינטרנט, כמו מאגרי קוד ב-Github או תיעוד טכני, מידע שלרוב כתוב ב-Markdown, לכן קל יותר למודלים לנתח את הפורמט הזה ולייצר אותו כפלט.
קובץ Markdown הוא שילוב בין טקסט קל לקריאה (Plain Text) לבין מבנה עשיר (Rich Text) אבל בלי ״רעש״ של תגיות ועיצובים. אבל בכל זאת אם אנחנו לא רוצים שה-AI יבזבז טוקנים ויעבוד בצורה יעילה יותר, אנחנו חייבים לייצר לו קונטקסט על המסמך, מידע שיעזור למודל לפני שהוא קורא את המסמך, המידע הזה נקרא YAML Frontmatter.
מה זה YAML Frontmatter ולמה זה קריטי לעבודה עם AI?
תדמיינו שאתם נכנסים לספרייה ענקית. על המדפים יש אלפי ספרים, אבל אין להם מידע על הכריכה, אין שם לספר, שם של הסופר, שנת פרסום או ז׳אנר. במקרה כזה כדי לדעת על מה הספר, היינו חייבים לפתוח אותו ולקרוא, תבינו ככה נראים המסמכים שלנו ל-AI, פשוט קובץ טקסט רגיל, בלי מידע

ה-YAML Frontmatter במילים פשוטות, זה “בלוק” של מידע שמופיע בתחילת הקובץ. הוא מופרד משאר הטקסט בשלושה מקפים (---) ומכיל מידע (Metadata) על הקובץ במבנה פשוט של מפתח וערך (כמו: תאריך: 2024-03-14). זה מידע שעוזר ל-AI לקבל הקשר על המסמך.
עכשיו דמיינו שלכל ספר מוצמדת מדבקה קטנה בראש העמוד הראשון עם פרטים כמו: שם הספר, ז’אנר ותאריך פרסום. המדבקה הזו היא בעצם ה-YAML Frontmatter.
אבל זה לא משמש רק AI אלא גם מערכות לניהול תוכן (CMS), למערכות ניהול מסמכים כמו Notion או Obsidian ומשמש גם כלי פיתוח וניהול גרסאות של קוד כמו Github.
למה זה חשוב כשעובדים עם בינה מלאכותית (AI)?
כשאנחנו עובדים עם מודלים כמו Claude-Code, בונים Skill׳ים או מערכות מבוססות סוכנים, ה-Frontmatter חשוב משלוש סיבות:
- מתן הקשר (Context) מדויק – כשאנחנו מזינים ל-AI קובץ עם Frontmatter, אנחנו לא צריכים להסביר לו “זהו מאמר שנכתב על ידי יוסי בשנת 2020”. ה-AI מזהה את המבנה הזה מיד ומבין את ההקשר של הטקסט באופן אוטומטי
- סדר בתוך הבלגן (ארגון ידע) – אם יש לנו מאות הערות בתוכנות כמו Obsidian או Notion, ה-Frontmatter מאפשר ל-AI לסנן ולמצוא לנו מידע ספציפי. למשל: “תמצא לי את כל הפרוטוקולים מהפגישות שסומנו כ’דחופות’ בחודש האחרון”. ה-AI מחפש את המילה “דחוף” בתוך ה-Frontmatter ולא מתבלבל עם טקסט רגיל.
- אוטומציה של משימות – ככה אנחנו יכולים להנחות את ה-AI למשל: “עבור על כל קבצי הבלוג פוסט שלי, אם ב-Frontmatter כתוב שהסטטוס הוא ‘טיוטה’, תוסיף להם פסקת סיכום”. ה-YAML Frontmatter משמש פה כמו “שלט רחוק” שדרכו ה-AI יודע על איזה קבצים לפעול ומה לעשות איתם.
איך נראה YAML Frontmatter?
הבלוק תמיד מופיע בתחילת הקובץ ותחום בין שתי שורות של שלושה מקפים (---):
---
title: "מדריך ל-YAML"
date: 2024-03-14
author: "ישראל ישראלי"
tags: [מדריך, פיתוח]
draft: false
---
תוכן הקובץ מתחיל כאן...מה צריך להכיל ה-YAML:
- מיקום המסמך חייב להופיע בשורה הראשונה של הקובץ
- פורמט הנתונים ב-YAML מבוססת מפתח וערך, למשל:
תאריך עדכון: 2024-03-14 - הפרדה של ה-YAML משאר התוכן באמצעות 3 מקפים (
---), לפניו ואחריו
איך כל זה קשור לעבודה עם סוכני AI
עכשיו שהבנו מה זה YAML, בואו נראה איך זה עובד בפועל עם סוכני AI.
כשאנחנו משלבים סוכנים בעבודה שלנו (סוכני AI הם כלי בינה מלאכותית שיכולים לבצע פעולות באופן עצמאי) חשוב שנגדיר להם איך לפעול, מה הם צריכים לבצע, איך תהליכים הם צריכים לנהל, איזה הרשאות יש להם, לאיזה כלים הם מחוברים וזה ממשיך.
כאן נכנסים לתמונה ׳סקילים׳ (Skills), אנחנו מוסיפים לסוכן יכולות כמו שליחת אימיילים, עדכון יומן או הפעלת קוד ומגדירים לו מה הוא צריך לעשות, איך לעשות את זה, מה מותר או אסור לו לעשות ובאיזה כלי.
בואו נדגים את זה על מקרה של סוכן סושיאל. לסוכן מהסוג הזה צריכה להיות יכולת (Skill) של פרסום ברשתות חברתיות. היכולת הזו תרכז את הדגשים לכתיבה עבור כל רשת למשל. אבל כדי שהסוכן ידע איזה ׳סקיל׳ להפעיל הוא צריך מידע ברור, כדי שהוא לא יבזבז הרבה טוקנים על קריאת מסמכים שלמים עד שהוא מגיע לסקיל המתאים.
כאן ה-YAML Frontmatter נכנס לתמונה. כשהסוכן ניגש לקובץ הוא קודם קורא את ה-YAML כדי להבין אם זה המסמך שמכיל את היכולת (Skill) הרלוונטית, אם לא הוא ממשיך הלאה עד שהוא מוצא וככה הוא לא ״מבזבז״ הרבה טוקנים מחלון ההקשר.
הבנתם? היכולת היא מסמך ה-Markdown, בראש המסמך יש בלוק YAML שנותן לסוכן מידע על המסמך כדי שהוא לא יצטרך לקרוא את כולו.
זה נכון לא רק לסקילים, זה נכון גם כשאנחנו רוצים לתת לסוכן לפרסם טיוטה שכתבנו, תחשבו שיש לכם מסמך עם ה-YAML הזה:
---
task type: "הפצה"
Channel: "LinkedIn"
Tone: "נלהב"
---
תוכן: הצלחנו לייצר סוכן סושיאל חדש שמפרסם תכנים באינטרנט באופן עצמאיאיך הסוכן יעבוד במקרה הזה:
- הסוכן סורק את ה-YAML ומזהה את המפתח ״הפצה״
- המילה הזו מפעילה את היכולת (Skill) של פרסום
- הוא רואה שה-
channel: "LinkedIn"וככה הוא יודע מה ערוץ ההפצה - הוא רואה את הסגנון ב-
Toneויודע איך לסגנן את הפוסט - רק אז הוא קורא את התוכן
אם ה-task_type היה ״הופץ״ הסוכן היה פשוט ממשיך הלאה.
לסיכום
עבודה עם קבצים Markdown ו-YAML מאפשרת לייצר דיוק, ככה שהסוכן לא ״מנחש״ מה לעשות עם הקובץ, היא מאפשרת עבודה מהירה ויעילה, כי במקום לקרוא את כל המסמך, קוראים 4 שורות ויודעים אם הוא רלוונטי ומה צריך לעשות איתו, ככה אפשר לייצר אוטומציות ולנהל מאות קבצים שהסוכנים שלהם יודעים מה לעשות איתם רק באמצעות ה״מדבקה״ ששמתם בראש הקובץ.